
 MENU
MENU Eighteen papers by CSE researchers at NeurIPS 2025
Researchers affiliated with Computer Science and Engineering (CSE) at the University of Michigan are presenting 18 papers at the 2025 Conference on Neural Information Processing Systems (NeurIPS), one of the world’s leading conferences in machine learning, artificial intelligence, and computational neuroscience. This year’s event is being held in Mexico City, Mexico, from November 30 to December 5 and in San Diego, CA, on December 2-7.
New research by CSE authors covers topics including graph neural networks, algorithmic efficiency, strategic AI behavior, energy optimization, differential privacy, multimodal AI systems, and more. The papers being presented are as follows, with the names of authors affiliated with CSE in bold:
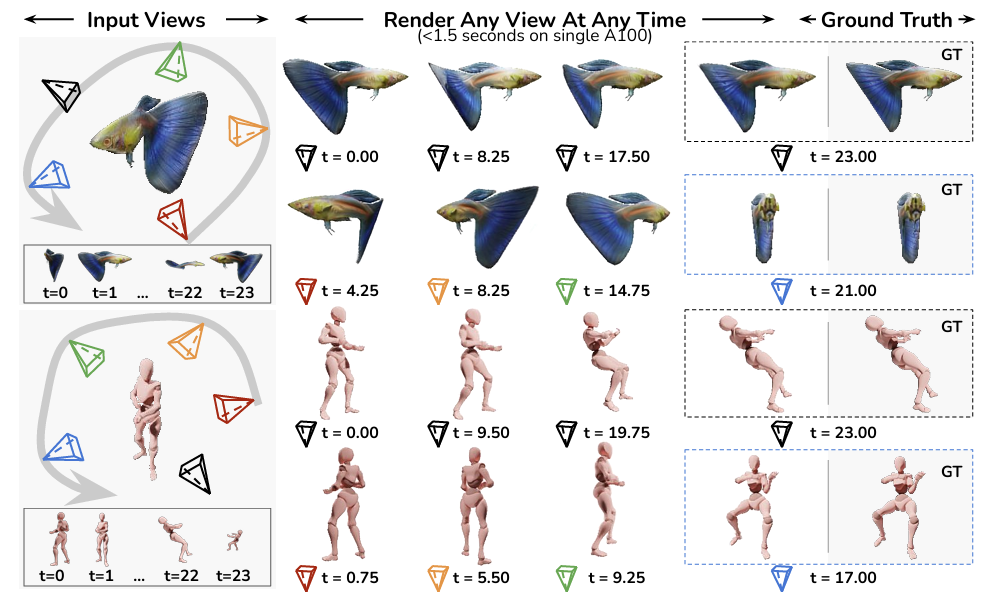
4D-LRM: Large Space-Time Reconstruction Model From and To Any View at Any Time
Ziqiao Ma, Xuweiyi Chen, Shoubin Yu, Sai Bi, Kai Zhang, Ziwen Chen, Sihan Xu, Jianing Yang, Zexiang Xu, Kalyan Sunkavalli, Mohit Bansal, Joyce Chai, Hao Tan
Abstract: Can we scale 4D pretraining to learn general space-time representations that reconstruct an object from a few views at some times to any view at any time? We provide an affirmative answer with 4D-LRM, the first large-scale 4D reconstruction model that takes input from unconstrained views and timestamps and renders arbitrary novel view-time combinations. Unlike prior 4D approaches, e.g., optimization-based, geometry-based, or generative, that struggle with efficiency, generalization, or faithfulness, 4D-LRM learns a unified space-time representation and directly predicts per-pixel 4D Gaussian primitives from posed image tokens across time, enabling fast, high-quality rendering at, in principle, infinite frame rate. Our results demonstrate that scaling spatiotemporal pretraining enables accurate and efficient 4D reconstruction. We show that 4D-LRM generalizes to novel objects, interpolates across time, and handles diverse camera setups. It reconstructs 24-frame sequences in one forward pass with less than 1.5 seconds on a single A100 GPU.
Random Search Neural Networks for Efficient and Expressive Graph Learning
Michael Ito, Danai Koutra, Jenna Wiens
Abstract: Random walk neural networks (RWNNs) have emerged as a promising approach for graph representation learning, leveraging recent advances in sequence models to process random walks. However, under realistic sampling constraints, RWNNs often fail to capture global structure even in small graphs due to incomplete node and edge coverage, limiting their expressivity. To address this, we propose \textit{random search neural networks} (RSNNs), which operate on random searches, each of which guarantees full node coverage. Theoretically, we demonstrate that in sparse graphs, only O(log|V|) searches are needed to achieve full edge coverage, substantially reducing sampling complexity compared to the O(|V|) walks required by RWNNs (assuming walk lengths scale with graph size). Furthermore, when paired with universal sequence models, RSNNs are universal approximators. We lastly show RSNNs are probabilistically invariant to graph isomorphisms, ensuring their expectation is an isomorphism-invariant graph function. Empirically, RSNNs consistently outperform RWNNs on molecular and protein benchmarks, achieving comparable or superior performance with up to 16× fewer sampled sequences. Our work bridges theoretical and practical advances in random walk based approaches, offering an efficient and expressive framework for learning on sparse graphs.
Position: Towards Bidirectional Human-AI Alignment
Hua Shen, Tiffany Knearem, Reshmi Ghosh, Kenan Alkiek, Kundan Krishna, Yachuan Liu, Ziqiao Ma, Savvas Petridis, Yi-Hao Peng, Li Qiwei, Sushrita Rakshit, Chenglei Si, Yutong Xie, Jeffrey Bigham, Frank Bentley, Joyce Chai, Zachary Lipton, Qiaozhu Mei, Michael Terry, Diyi Yang, Meredith Morris, Paul Resnick, David Jurgens
Abstract: Recent advances in general-purpose AI underscore the urgent need to align AI systems with human goals and values. Yet, the lack of a clear, shared understanding of what constitutes “alignment” limits meaningful progress and cross-disciplinary collaboration. In this position paper, we argue that the research community should explicitly define and critically reflect on “alignment” to account for the bidirectional and dynamic relationship between humans and AI. Through a systematic review of over 400 papers spanning HCI, NLP, ML, and more, we examine how alignment is currently defined and operationalized. Building on this analysis, we introduce the Bidirectional Human-AI Alignment framework, which not only incorporates traditional efforts to align AI with human values but also introduces the critical, underexplored dimension of aligning humans with AI — supporting cognitive, behavioral, and societal adaptation to rapidly advancing AI technologies. Our findings reveal significant gaps in current literature, especially in long-term interaction design, human value modeling, and mutual understanding. We conclude with three central challenges and actionable recommendations to guide future research toward more nuanced, reciprocal, and human-AI alignment approaches.

Disentangling misreporting from genuine adaptation in strategic settings: a causal approach
Dylan Zapzalka, Trenton Chang, Lindsay Warrenburg, Sae-Hwan Park, Daniel Shenfeld, Ravi Parikh, Jenna Wiens, Maggie Makar
Abstract: In settings where ML models are used to inform the allocation of resources, agents affected by the allocation decisions might have an incentive to strategically change their features to secure better outcomes. While prior work has studied strategic responses broadly, disentangling misreporting from genuine adaptation remains a fundamental challenge. In this paper, we propose a causally-motivated approach to identify and quantify how much an agent misreports on average by distinguishing deceptive changes in their features from genuine adaptation. Our key insight is that, unlike genuine adaptation, misreported features do not causally affect downstream variables (i.e., causal descendants). We exploit this asymmetry by comparing the causal effect of misreported features on their causal descendants as derived from manipulated datasets against those from unmanipulated datasets to identify the misreporting rate. We empirically validate our theoretical results using a semi-synthetic and real Medicare dataset with misreported data, demonstrating that our approach can be employed to identify misreporting in real-world scenarios.
What Happens During the Loss Plateau? Understanding Abrupt Learning in Transformers
Pulkit Gopalani, Wei Hu
Abstract: Training Transformers on algorithmic tasks frequently demonstrates an intriguing abrupt learning phenomenon: an extended performance plateau followed by a sudden, sharp improvement. This work investigates the underlying mechanisms for such dynamics, primarily in shallow Transformers. We reveal that during the plateau, the model often develops an interpretable partial solution while simultaneously exhibiting a strong repetition bias in their outputs. This output degeneracy is accompanied by internal representation collapse, where hidden states across different tokens become nearly parallel. We further identify the slow learning of optimal attention maps as a key bottleneck. Hidden progress in attention configuration during the plateau precedes the eventual rapid convergence, and directly intervening on attention significantly alters plateau duration and the severity of repetition bias and representational collapse. We validate that these identified phenomena-repetition bias and representation collapse-are not artifacts of toy setups but also manifest in the early pre-training stage of large language models like Pythia and OLMo.
MLRC-Bench: Can Language Agents Solve Machine Learning Research Challenges?
Yunxiang Zhang, Muhammad Khalifa, Shitanshu Bhushan, Grant Murphy, Lajanugen Logeswaran, Jaekyeom Kim, Moontae Lee, Honglak Lee, Lu Wang
Abstract: We introduce MLRC-Bench, a benchmark designed to quantify how effectively language agents can tackle challenging Machine Learning (ML) Research Competitions, with a focus on open research problems that demand novel methodologies. Unlike prior work, e.g., AI Scientist, which evaluates the end-to-end agentic pipeline by using LLM-as-a-judge, MLRC-Bench measures the key steps of proposing and implementing novel research methods and evaluates them with rigorous protocol and objective metrics. Our curated suite of 7 competition tasks reveals significant challenges for LLM agents. Even the best-performing tested agent (gemini-exp-1206 under MLAB) closes only 9.3% of the gap between baseline and top human participant scores. Furthermore, our analysis reveals a misalignment between the LLM-judged innovation and actual performance on cutting-edge ML research problems. MLRC-Bench is a dynamic benchmark, designed to grow with new ML competitions and encourage rigorous, objective evaluations of AI research capabilities.

MMTU: A Massive Multi-Task Table Understanding and Reasoning Benchmark
Junjie Xing, Yeye He, Mengyu Zhou, Haoyu Dong, Shi Han, Lingjiao Chen, Dongmei Zhang, Surajit Chaudhuri, H. V. Jagadish
Abstract: Tables and table-based use cases play a crucial role in many important real-world applications, such as spreadsheets, databases, and computational notebooks, which traditionally require expert-level users like data engineers, data analysts, and database administrators to operate. Although LLMs have shown remarkable progress in working with tables (e.g., in spreadsheet and database copilot scenarios), comprehensive benchmarking of such capabilities remains limited. In contrast to an extensive and growing list of NLP benchmarks, evaluations of table-related tasks are scarce, and narrowly focus on tasks like NL-to-SQL and Table-QA, overlooking the broader spectrum of real-world tasks that professional users face. This gap limits our understanding and model progress in this important area.
In this work, we introduce MMTU, a large-scale benchmark with over 28K questions across 25 real-world table tasks, designed to comprehensively evaluate models ability to understand, reason, and manipulate real tables at the expert-level. These tasks are drawn from decades’ worth of computer science research on tabular data, with a focus on complex table tasks faced by professional users. We show that MMTU require a combination of skills — including table understanding, reasoning, and coding — that remain challenging for today’s frontier models, where even frontier reasoning models like OpenAI GPT-5 and DeepSeek R1 score only around 69\% and 57\% respectively, suggesting significant room for improvement. We highlight key findings in our evaluation using MMTU and hope that this benchmark drives further advances in understanding and developing foundation models for structured data processing and analysis.
The ML.ENERGY Benchmark: Toward Automated Inference Energy Measurement and Optimization
Jae-Won Chung, Jeff J. Ma, Ruofan Wu, Jiachen Liu, Oh Jun Kweon, Yuxuan Xia, Zhiyu Wu, Mosharaf Chowdhury
Abstract: As the adoption of Generative AI in real-world services grow explosively, energy has emerged as a critical bottleneck resource. However, energy remains a metric that is often overlooked, under-explored, or poorly understood in the context of building ML systems. We present the ML.ENERGY Benchmark, a benchmark suite and tool for measuring inference energy consumption under realistic service environments, and the corresponding ML.ENERGY Leaderboard, which have served as a valuable resource for those hoping to understand and optimize the energy consumption of their generative AI services. In this paper, we explain four key design principles for benchmarking ML energy we have acquired over time, and then describe how they are implemented in the ML.ENERGY Benchmark. We then highlight results from the early 2025 iteration of the benchmark, including energy measurements of 40 widely used model architectures across 6 different tasks, case studies of how ML design choices impact energy consumption, and how automated optimization recommendations can lead to significant (sometimes more than 40%) energy savings without changing what is being computed by the model. The ML.ENERGY Benchmark is open-source and can be easily extended to various customized models and application scenarios.

What Really is a Member? Discrediting Membership Inference via Poisoning
Neal Mangaokar, Ashish Hooda, Zhuohang Li, Bradley Malin, Kassem Fawaz, Somesh Jha, Atul Prakash, Amrita Roy Chowdhury
Abstract: Membership inference tests aim to determine whether a particular data point was included in a language model’s training set. However, recent works have shown that such tests often fail under the strict definition of membership based on exact matching, and have suggested relaxing this definition to include semantic neighbors as members as well. In this work, we show that membership inference tests are still unreliable under this relaxation – it is possible to poison the training dataset in a way that causes the test to produce incorrect predictions for a target point. We theoretically reveal a trade-off between a test’s accuracy and its robustness to poisoning. We also present a concrete instantiation of this poisoning attack and empirically validate its effectiveness. Our results show that it can degrade the performance of existing tests to well below random.
Fine-grained Analysis and Faster Algorithms for Iteratively Solving Linear Systems
Michał Dereziński, Daniel LeJeune, Deanna Needell, Elizaveta Rebrova
Abstract: Despite being a key bottleneck in many machine learning tasks, the cost of solving large linear systems has proven challenging to quantify due to problem-dependent quantities such as condition numbers. To tackle this, we consider a fine-grained notion of complexity for solving linear systems, which is motivated by applications where the data exhibits low-dimensional structure, including spiked covariance models and kernel machines, and when the linear system is explicitly regularized, such as ridge regression. Concretely, let κℓ be the ratio between the ℓth largest and the smallest singular value of n×n matrix A. We give a stochastic algorithm based on the Sketch-and-Project paradigm, that solves the linear system Ax=b, that is, finds such that ‖Ax−b‖≤ϵ‖b‖, in time O(κℓ⋅n2log1/ϵ), for any ℓ=O(n0.729). This is a direct improvement over preconditioned conjugate gradient, and it provides a stronger separation between stochastic linear solvers and algorithms accessing A only through matrix-vector products. Our main technical contribution is the new analysis of the first and second moments of the random projection matrix that arises in Sketch-and-Project.
Turbocharging Gaussian Process Inference with Approximate Sketch-and-Project
Pratik Rathore, Zachary Frangella, Sachin Garg, Shaghayegh Fazliani, Michał Dereziński, Madeleine Udell
Abstract: Gaussian processes (GPs) play an essential role in biostatistics, scientific machine learning, and Bayesian optimization for their ability to provide probabilistic predictions and model uncertainty. However, GP inference struggles to scale to large datasets (which are common in modern applications), since it requires the solution of a linear system whose size scales quadratically with the number of samples in the dataset. We propose an approximate, distributed, accelerated sketch-and-project algorithm (𝙰𝙳𝙰𝚂𝙰𝙿) for solving these linear systems, which improves scalability. We use the theory of determinantal point processes to show that the posterior mean induced by sketch-and-project rapidly converges to the true posterior mean. In particular, this yields the first efficient, condition number-free algorithm for estimating the posterior mean along the top spectral basis functions, showing that our approach is principled for GP inference. 𝙰𝙳𝙰𝚂𝙰𝙿 outperforms state-of-the-art solvers based on conjugate gradient and coordinate descent across several benchmark datasets and a large-scale Bayesian optimization task. Moreover, 𝙰𝙳𝙰𝚂𝙰𝙿 scales to a dataset with over 3 × 10^8 samples, a feat that has not been accomplished in the literature.
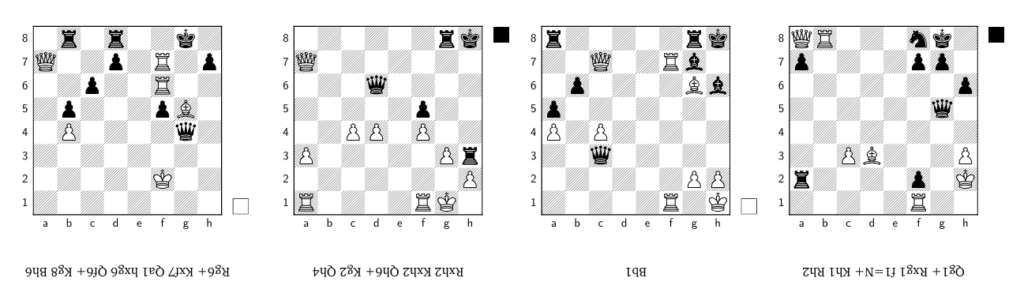
Generating Creative Chess Puzzles
Xidong Feng, Vivek Veeriah, Marcus Chiam, Michael Dennis, Federico Barbero, Johan Obando Ceron, Jiaxin Shi, Satinder Singh, Shaobo Hou, Nenad Tomasev, Tom Zahavy
Abstract: While Generative AI rapidly advances in various domains, generating truly creative, aesthetic, and counter-intuitive outputs remains a challenge. This paper presents an approach to tackle these difficulties in the domain of chess puzzles. We start by benchmarking Generative AI architectures, and then introduce an RL framework with novel rewards based on chess engine search statistics to overcome some of those shortcomings. The rewards are designed to enhance a puzzle’s uniqueness, counter-intuitiveness, diversity, and realism. Our RL approach dramatically increases counter-intuitive puzzle generation by 10x, from 0.22\% (supervised) to 2.5\%, surpassing existing dataset rates (2.1\%) and the best Lichess-trained model (0.4\%). Our puzzles meet novelty and diversity benchmarks, retain aesthetic themes, and are rated by human experts as more creative, enjoyable, and counter-intuitive than composed book puzzles, even approaching classic compositions. Our final outcome is a curated booklet of these AI-generated puzzles, which is acknowledged for creativity by three world-renowned experts.
Plasticity as the Mirror of Empowerment
David Abel, Michael Bowling, Andre Barreto, Will Dabney, Shi Dong, Steven Hansen, Anna Harutyunyan, Khimya Khetarpal, Clare Lyle, Razvan Pascanu, Georgios Piliouras, Doina Precup, Jonathan Richens, Mark Rowland, Tom Schaul, Satinder Singh
Abstract: Agents are minimally entities that are influenced by their past observations and act to influence future observations. This latter capacity is captured by empowerment, which has served as a vital framing concept across artificial intelligence and cognitive science. This former capacity, however, is equally foundational: In what ways, and to what extent, can an agent be influenced by what it observes? In this paper, we ground this concept in a universal agent-centric measure that we refer to as plasticity, and reveal a fundamental connection to empowerment. Following a set of desiderata on a suitable definition, we define plasticity using a new information-theoretic quantity we call the generalized directed information. We show that this new quantity strictly generalizes the directed information introduced by Massey (1990) while preserving all of its desirable properties. Under this definition, we find that plasticity is well thought of as the mirror of empowerment: The two concepts are defined using the same measure, with only the direction of influence reversed. Our main result establishes a tension between the plasticity and empowerment of an agent, suggesting that agent design needs to be mindful of both characteristics. We explore the implications of these findings, and suggest that plasticity, empowerment, and their relationship are essential to understanding agency.
Improved Approximation Algorithms for Chromatic and Pseudometric-Weighted Correlation Clustering
Chenglin Fan, Dahoon Lee, Euiwoong Lee
Abstract: Correlation Clustering (CC) is a foundational problem in unsupervised learning that models binary similarity relations using labeled graphs. While classical CC has been widely studied, many real-world applications involve more nuanced relationships, either multi-class categorical interactions or varying confidence levels in edge labels. To address these, two natural generalizations have been proposed: Chromatic Correlation Clustering (CCC), which assigns semantic colors to edge labels, and pseudometric-weighted CC, which allows edge weights satisfying the triangle inequality. In this paper, we develop improved approximation algorithms for both settings. Our approach leverages LP-based pivoting techniques combined with problem-specific rounding functions. For the pseudometric-weighted correlation clustering problem, we present a tight 10/3-approximation algorithm, matching the best possible bound achievable within the framework of standard LP relaxation combined with specialized rounding. For the Chromatic Correlation Clustering (CCC) problem, we improve the approximation ratio from the previous best of 2.5 to 2.15, and we establish a lower bound of 2.11 within the same analytical framework, highlighting the near-optimality of our result.
Active Test-time Vision-Language Navigation
Heeju Ko, Sung June Kim, Gyeongrok Oh, Jeongyoon Yoon, Honglak Lee, Sujin Jang, Seungryong Kim, Sangpil Kim
Abstract: Vision-Language Navigation (VLN) policies trained on offline datasets often exhibit degraded task performance when deployed in unfamiliar navigation environments at test time, where agents are typically evaluated without access to external interaction or feedback. Entropy minimization has emerged as a practical solution for reducing prediction uncertainty at test time; however, it can suffer from accumulated errors, as agents may become overconfident in incorrect actions without sufficient contextual grounding. To tackle these challenges, we introduce ATENA (Active TEst-time Navigation Agent), a test-time active learning framework that enables a practical human-robot interaction via episodic feedback on uncertain navigation outcomes. In particular, ATENA learns to increase certainty in successful episodes and decrease it in failed ones, improving uncertainty calibration. Here, we propose mixture entropy optimization, where entropy is obtained from a combination of the action and pseudo-expert distributions-a hypothetical action distribution assuming the agent’s selected action to be optimal-controlling both prediction confidence and action preference. In addition, we propose a self-active learning strategy that enables an agent to evaluate its navigation outcomes based on confident predictions. As a result, the agent stays actively engaged throughout all iterations, leading to well-grounded and adaptive decision-making. Extensive evaluations on challenging VLN benchmarks-REVERIE, R2R, and R2R-CE-demonstrate that ATENA successfully overcomes distributional shifts at test time, outperforming the compared baseline methods across various settings.

Benign Overfitting in Single-Head Attention
Roey Magen, Shuning Shang, Zhiwei Xu, Spencer Frei, Wei Hu, Gal Vardi
Abstract: The phenomenon of benign overfitting, where a trained neural network perfectly fits noisy training data but still achieves near-optimal test performance, has been extensively studied in recent years for linear models and fully-connected/convolutional networks. In this work, we study benign overfitting in a single-head softmax attention model, which is the fundamental building block of Transformers. We prove that under appropriate conditions, the model exhibits benign overfitting in a classification setting already after two steps of gradient descent. Moreover, we show conditions where a minimum-norm/maximum-margin interpolator exhibits benign overfitting. We study how the overfitting behavior depends on the signal-to-noise ratio (SNR) of the data distribution, namely, the ratio between norms of signal and noise tokens, and prove that a sufficiently large SNR is both necessary and sufficient for benign overfitting.
KL Penalty Control via Perturbation for Direct Preference Optimization
Sangkyu Lee, Janghoon Han, Hosung Song, Stanley Jungkyu Choi, Honglak Lee, Youngjae Yu
Abstract: Direct Preference Optimization (DPO) demonstrates the advantage of aligning a large language model with human preference using only an offline dataset. However, DPO has the limitation that the KL penalty, which prevents excessive deviation from the reference model, is static throughout the training process. Several methods claim to change this static KL penalty of DPO into a dynamic one, but no approach can adaptively assign different KL penalties for each preference pair. In this paper, we propose ε-Direct Preference Optimization (ε-DPO), which allows adaptive control of the KL penalty strength β for each preference pair. Specifically, ε-DPO adaptively controls β for each preference pair based on the monotonicity of logits as a preference model under the perturbation of β during training. This is equivalent to adjusting the KL penalty by checking whether the change in training-time temperature can lead to better preference confidence as preference models by simply reusing the logit of the current policy and the reference policy. Experimental results show that the simple criterion of ε-DPO for KL penalty relaxation significantly improves DPO compared to most existing direct alignment algorithms on general chatbot benchmarks and reveal that this KL penalty control criterion can reflect confusion as a preference model and provide an efficient KL trade-off, highlighting the significance of instance-level adaptive KL penalty control in DPO.
Differentially Private Quantiles with Smaller Error
Jacob Imola, Fabrizio Boninsegna, Hannah Keller, Anders Aamand, Amrita Roy Chowdhury, Rasmus Pagh
Abstract: In the approximate quantiles problem, the goal is to output m quantile estimates, the ranks of which are as close as possible to m given quantiles q1,…,qm. We present a mechanism for approximate quantiles that satisfies ε-differential privacy for a dataset of n real numbers where the ratio between the closest pair of points and the size of the domain is bounded by b. As long as the minimum gap between quantiles is large enough, |qi−qi−1|≥Ω(mlog(m)log(b)nε) for all i, the maximum rank error of our mechanism is O(log(b)+log2(m)ε) with high probability. Previously, the best known algorithm under pure DP was due to Kaplan, Schnapp, and Stemmer~(ICML ’22), who achieve a bound of O(log(b)log2(m)/ε), so we save a factor Ω(min(log(b),log2(m))). Our improvement stems from the use of continual counting techniques to randomize the quantiles in a correlated way. We also present an (ε,δ)-differentially private mechanism that relaxes the gap assumption without affecting the error bound, improving on existing methods when δ is sufficiently close to zero. We provide experimental evaluation which confirms that our mechanism performs favorably compared to prior work in practice, in particular when the number of quantiles m is large.